During the time I wrote my last article about finetuning AlexNet with TensorFlow I read about the best practices for optimizing performance in TensorFlow. There are several things I made different to these practices but I think the one that had the biggest effect on the performance was everything around the input pipeline. With the new Version of TensorFlow the Dataset API was introduced and provides us with a good and relatively easy way to write our own input pipeline using nothing more than TensorFlow. While you can potentially use this Datasets for any kind of input data, I will use images for the use case of this article. By the end of this article you will hopefully be able to use the new Dataset API for you own project and decrease the computation time needed to train you model.
What we had so far?
What I used so far (and saw the most around the Internet) was loading images and preprocessing them with external libraries (e.g. OpenCV) and feeding them into the model using the feed_dict method. Well, in the performance guide they say, that this method is suboptimal. They propose using queues. I spend a lot of time to work myself into the usage of these queues (and already started to write an article about this topic) but to be honest it was quite a pain to work with them. Also I liked the idea of queues, they had some problems I couldn’t solve (e.g. training and validating a model in the same session by switching between different input queues, one for training and one for validation data).
What we got now
For me, everything started to change when I found this issue, where they announced to design a new input pipeline API. I wasn’t by far the only one who was struggling with the queue-way-of-doing-it. And as it seemed, they where aware of the fact and wanted to create a better input pipeline API (well, thanks to competition I would say..).
The core of the new input pipeline is the Dataset (and maybe the Iterator). A Dataset is a collection of elements, each with the same structure, where one element can be one of more tensors. The different tensors inside an element are called components. Each component has a certain data type and shape, but different components inside one element can have different data types and shapes. For illustration purpose I’ll give an example in pseudo-code, where I represent one dataset as Python-List and an element as a Tuple
# This is pseudo code
dataset1 = [ (img1, [1, 0, 0]),
(img2, [0, 1, 0]),
(img3, [1, 0, 0]),
(img4, [0, 0, 1]),
(img5, [0, 1, 0])
]
If dataset1 would be a TensorFlow Dataset, then each Tuple is an element consisting of two components. The first component is a 3D tensors containing an image (for visibility I just gave them a name and didn’t try to write a three times nested list) and the second component is a vector containing symbolically the one-hot-encoding class vector. The image component would have a data type of tf.float32, where as the data type of the vector would be some tf.int.
We could now use an Iterator to get element by element from this dataset. How you get batches of data will be shown later in this tutorial.
Toy example of the input pipeline
I think the concept can be better explained given some simple toy example. Note, that there are many different ways how you can create a dataset but I’ll talk only about the one I used the most for my image classification models (for a full list of possibilities look here). There I usually have text file storing the path to the images and there class label in one row. Imagine you have all paths and labels read in into two different lists, this is were we start:
import tensorflow as tf
from tensorflow.contrib.data import Dataset, Iterator
# Toy data
train_imgs = tf.constant(['train/img1.png', 'train/img2.png',
'train/img3.png', 'train/img4.png',
'train/img5.png', 'train/img6.png'])
train_labels = tf.constant([0, 0, 0, 1, 1, 1])
val_imgs = tf.constant(['val/img1.png', 'val/img2.png',
'val/img3.png', 'val/img4.png'])
val_labels = tf.constant([0, 0, 1, 1])
# create TensorFlow Dataset objects
tr_data = Dataset.from_tensor_slices((train_imgs, train_labels))
val_data = Dataset.from_tensor_slices((val_imgs, val_labels))
# create TensorFlow Iterator object
iterator = Iterator.from_structure(tr_data.output_types,
tr_data.output_shapes)
next_element = iterator.get_next()
# create two initialization ops to switch between the datasets
training_init_op = iterator.make_initializer(tr_data)
validation_init_op = iterator.make_initializer(val_data)
with tf.Session() as sess:
# initialize the iterator on the training data
sess.run(training_init_op)
# get each element of the training dataset until the end is reached
while True:
try:
elem = sess.run(next_element)
print(elem)
except tf.errors.OutOfRangeError:
print("End of training dataset.")
break
# initialize the iterator on the validation data
sess.run(validation_init_op)
# get each element of the validation dataset until the end is reached
while True:
try:
elem = sess.run(next_element)
print(elem)
except tf.errors.OutOfRangeError:
print("End of training dataset.")
break
This should print:
(b'train/img1.png', 0)
(b'train/img2.png', 0)
(b'train/img3.png', 0)
(b'train/img4.png', 1)
(b'train/img5.png', 1)
(b'train/img6.png', 1)
End of training dataset.
(b'val/img1.png', 0)
(b'val/img2.png', 0)
(b'val/img3.png', 1)
(b'val/img4.png', 1)
End of training dataset.
Isn’t that wonderful? I don’t know if you have played around with TensorFlows Queues but this is simple, clear and works like a charm.
Working with images
Of course it’s not of interest for us to print out image paths and label numbers. Instead what we would like to do is loading the image to which the path points, maybe doing some preprocessing (and augmentation) and converting the label number into a one-hot-encoding, as we need them for training any image classification network. This can be achieved by writing a parsing function and using the .map(f) functionality of the Datasets. The .map(f) function creates a new dataset by applying a function f to every element of the original dataset. This function could be any Python function, also including other Python libraries, but regarding performance it’s recommended to use only Tensorflow functionality. We don’t want anything special for the moment, so this could be our parsing function:
import tensorflow as tf
# let's assume we have two classes in our dataset
NUM_CLASSES = 2
def input_parser(img_path, label):
# convert the label to one-hot encoding
one_hot = tf.one_hot(label, NUM_CLASSES)
# read the img from file
img_file = tf.read_file(img_path)
img_decoded = tf.image.decode_image(img_file, channels=3)
return img_decoded, one_hot
Taking the toy example from above, all we have to add is this line:
#e.g. for the training dataset
tr_data = tr_data.map(input_parser)
Now the first component of each element in the dataset, which we obtain by calling next_element wouldn’t be the string to the image path, it would be a 3D-tensor storing the image. And for the second component, we wouldn’t get the label number, but the one-hot-encoding. Pretty neat, isn’t it?
For the practical use case it would make sense to have two different parsing functions. One function would be used for images from the training set, for which we often perform data augmentation additional to resizing (and maybe centering). The other function would logically be for the inference case, for which we only want to load the images and resize them according to the expected model input (and eventually center as well).
Usually we also don’t want a single image to train our model, but mini-batches for various images. With the new Dataset API this is also a one-lines:
dataset = dataset.batch(batch_size)
As with the .map() function from above, this can be done by calling the batch(n) function on the dataset, which will create a new dataset with batches of n elements per batch.
Attention: The only functionality I’m struggling with, is the .shuffle(buffer_size) function. This, like the map() and .batch() function, can be applied on a dataset, to create a new dataset, loads the first buffer_size elements into memory and shuffles them. Here I explained the problem, given an example, that can arise from this function, that we as users need to be aware of. But in short: If your initial list of samples (image path + label) is ordered, so that you all samples of the first class in the beginning, followed by all samples of the second class etc., and your buffer_size is smaller than the number of samples you have of each class, you will have batches with samples of only one class and your model will not train. Therefore we need to take care of an initial shuffling ourselves and not rely on TensorFlows shuffling.
Performance comparison
To measure the performance using the new input pipeline from TensorFlow instead of external libraries, I adapted my code from the finetuning AlexNet with TensorFlow article. Previously I used OpenCV to load and preprocess the images whereas now the input pipeline (implemented in the datagenerator.py file) uses only TensorFlow functions. All parameters, such as batch_size, trainable layers etc. stayed the same for both runs.
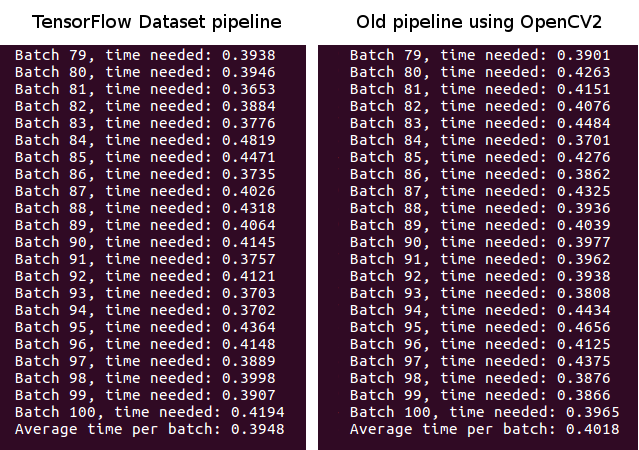
To be honest, I was a bit disappointed when I saw these numbers. There effect is negligible, but hey! we have our input pipeline with nothing more than TensorFlow. I didn’t do much more tests, but maybe the positive effect increases if we apply more functionality to the input pipeline (such as random augmentation).
As it seems, the Dataset is not based on Queues. This leads to the old problem, that we can’t use CPU and GPU efficiently, meaning that while the GPU processes on batch of data the CPU loads and preprocesses data in parallel. So when the GPU needs a new batch of data, the data is already in memory and can be passed immediately to the GPU. This can be achived with TensorFlow Queues but than you can’t train and validate you model in one session (at least I couldn’t find a way to do so).
Conclusion
The main advantage of the new input pipeline API from Tensorflow is in my eyes the clear structure and the simplicity. It’s pretty easy to add any functionality you want, as well as switching between different input data streams. Regarding the Performance I couldn’t find much of a speedup, but we’ll see what further development of TensorFlow brings.
Regarding code examples: I update the code of the GitHub repository of my last article, so that you can find an example on how to finetune AlexNet using the new input pipeline there.