When I wrote the last article about the new Dataset API TensorFlow got with the release of version 1.2, it was still only a release candidate and the documentation was pretty bad. There was a good discussion about the new input pipeline on GitHub and in the last comment Derek Murry pointed me to two additional arguments you can provide to the Dataset API to make the whole input pipeline work in parallel, instead of sequentially.

Documentation of the .map() function of the Dataset class from the official TensorFlow documentation
There are two optional arguments to the .map() function (which we use to apply a function to each element of the dataset), that make the whole magic: num_threads and output_buffer_size. I think these arguments don’t need much of an explanation and I’m not sure if this was just undocumented when I wrote the last article or if I was just blind.
Anyway, let’s have a look on the speed-up by finetuning AlexNet with and without these arguments provided. I’ll use the code from my GitHub repository and by the time of writing this, the code is already updated for you to run in parallel by default.
The only thing I changed was this piece of code from:
# distinguish between train/infer. when calling the parsing functions
if mode == 'training':
data = data.map(self._parse_function_train)
elif mode == 'inference':
data = data.map(self._parse_function_inference)
to:
# distinguish between train/infer. when calling the parsing functions
if mode == 'training':
data = data.map(self._parse_function_train, num_threads=8,
output_buffer_size=100*batch_size)
elif mode == 'inference':
data = data.map(self._parse_function_inference, num_threads=8,
output_buffer_size=100*batch_size)
And here is the speed comparison of the first 200 steps:
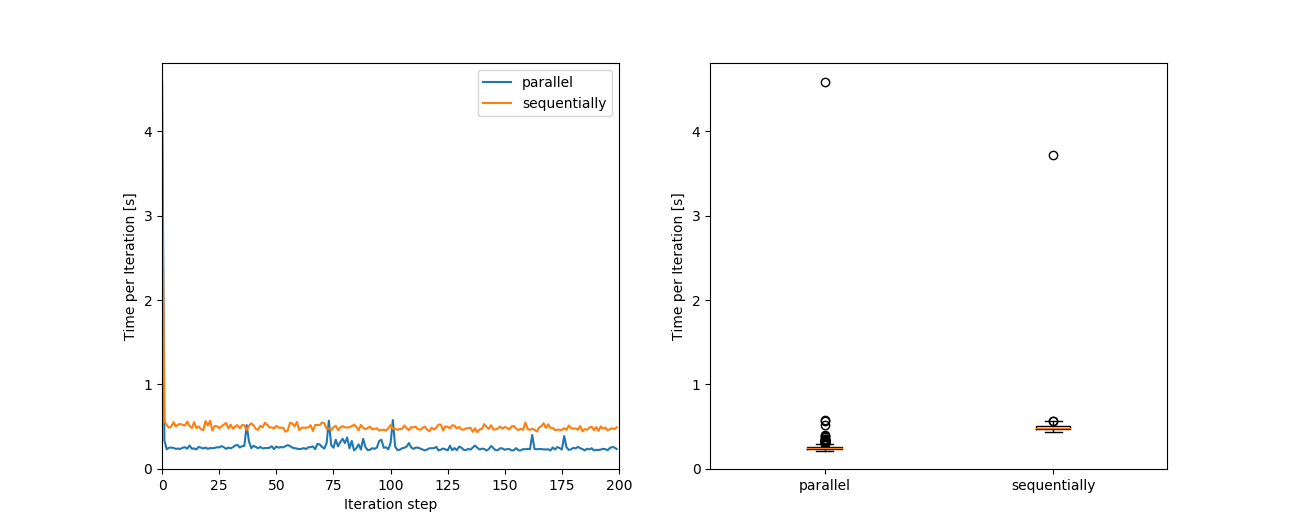
Comparision of the processing time per batch of the parallelized and the sequential input pipeline.
Surprise, surprise: the parallelized version is faster (roughly two times for my test settings.) That enhancing the speed is so easy with TensorFlow is indeed a surprise “cough” - and it wasn’t for sure with the old FIFO Queue. The initial step might take a bit longer (see the outlier in the boxplot), which I guess comes from filling the buffer, but for the rest, it runs quite a lot faster.
And since I set myself the goal to write shorter articles, that it for this time. Just remember: Always have a good look at the documentation or don’t complain about the speed.